|
|
文礼:专栏文章目录
自上一篇以来,又花了不到一周的时间将我们的路径跟踪器用老黄的OptiX 7重新写了一下,这下总算是进入了秒级出图(好吧,其实是15秒)。
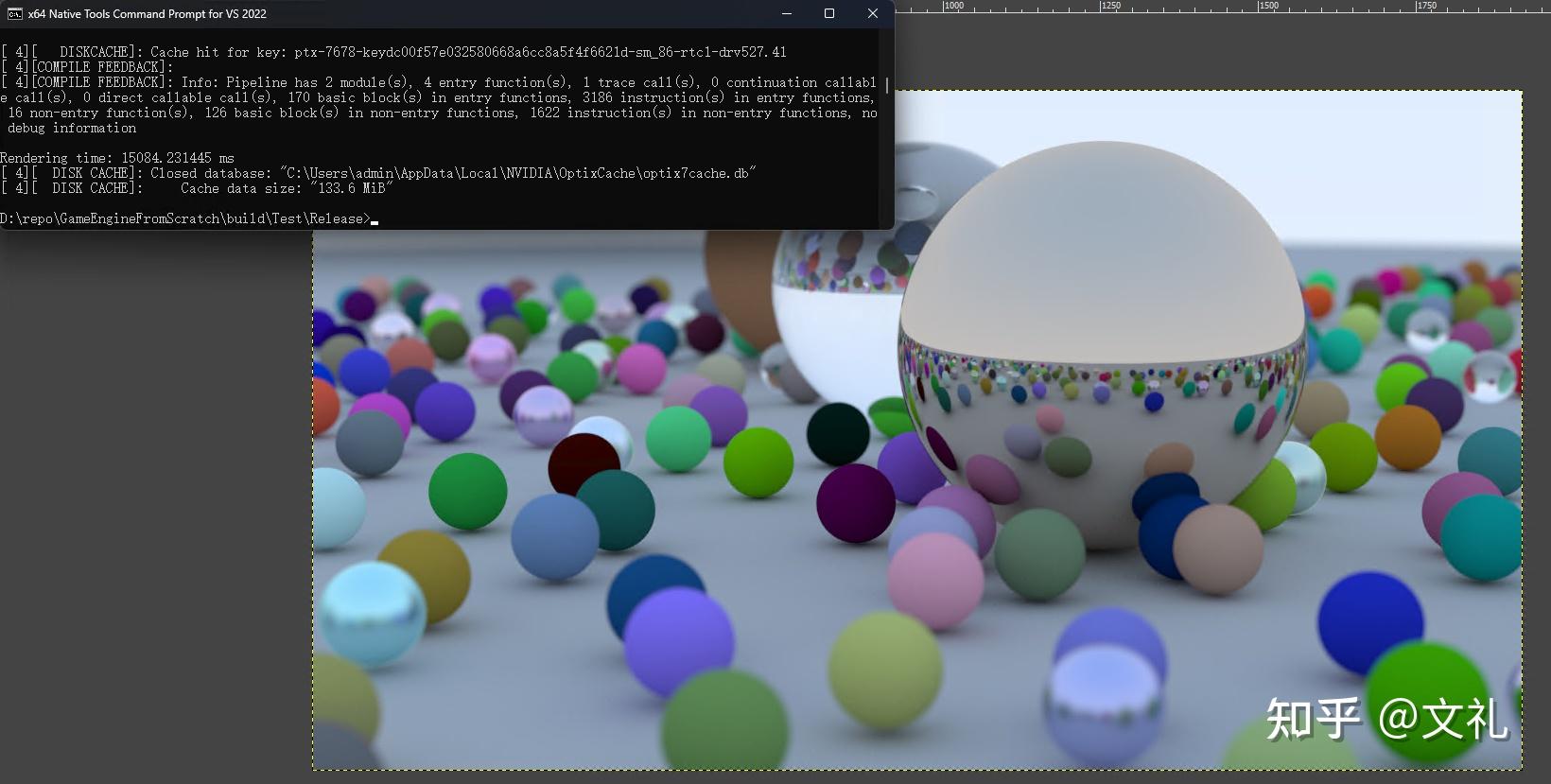
使用OptiX 7,在3070级别显卡达到15秒出图。(1920 x 1080,512spp,最大50次反弹/折射)
我觉得学习使用OptiX的过程,有助于对近年所谓的实时光线追踪的底层实现有一个较好较为清晰的理解。所以挺值得的。因为虽然OptiX本身的定位是为离线渲染器,以及那些无法升级最新图形API的游戏引擎(如Vulkan/DX12)提供一种支持光追的方法,但是毕竟是出自老黄本家,某种意义上更加接近硬件的本来面貌,没有那么多的抽象层夹在其中。
开发环境构筑
在写本文的时候,网上关于OptiX的资料并不是很多,尤其是好的中文资料。至少我搜索下来是这样。一开始我以为它是和CUDA、ISPC等并列的一种新的开发语言,但是实际上使用下来,它是基于CUDA的,一个光线追踪器的半成品框架。就有点类似MFC的那种感觉。
所以,使用OptiX,首先需要构筑CUDA的开发环境。而CUDA的开发环境,首先需要构筑C++的开发环境。我们这个系列因为是跨平台开发,用的是CMake+(各平台C++编译工具链)+(各平台SDK)的C++开发环境,然后在此基础上安装CUDA的SDK(到老黄家去下载,需要注册开发者账户,免费),然后再下载OptiX的SDK安装。
关于如何在CMake当中统合CUDA的编译,请参照上一篇。而OptiX因为其实是一套框架模版,所以并没有独立的编译器。需要做的事情就是让CMake找到OptiX的头文件位置。目前CMake官方好像并没有对OptiX的支持,我是从github上面找了一个脚本,放在了项目的cmake脚本目录下:
# Looks for the environment variable:
# OPTIX76_PATH
# Sets the variables :
# OPTIX76_INCLUDE_DIR
# OptiX76_FOUND
set(OPTIX76_PATH $ENV{OPTIX76_PATH})
if ("${OPTIX76_PATH}" STREQUAL "")
if (WIN32)
# Try finding it inside the default installation directory under Windows first.
set(OPTIX76_PATH "C:/ProgramData/NVIDIA Corporation/OptiX SDK 7.6.0")
else()
# Adjust this if the OptiX SDK 7.6.0 installation is in a different location.
set(OPTIX76_PATH "~/NVIDIA-OptiX-SDK-7.6.0-linux64")
endif()
endif()
find_path(OPTIX76_INCLUDE_DIR optix_7_host.h ${OPTIX76_PATH}/include)
# message("OPTIX76_INCLUDE_DIR = " "${OPTIX76_INCLUDE_DIR}")
include(FindPackageHandleStandardArgs)
find_package_handle_standard_args(OptiX76 DEFAULT_MSG OPTIX76_INCLUDE_DIR)
mark_as_advanced(OPTIX76_INCLUDE_DIR)
# message("OptiX76_FOUND = " "${OptiX76_FOUND}")需要注意的是这个脚本其实也差不多就是硬编码,只对OptiX7.6有效。如果你是使用其它版本,需要修改它。或者你也可以直接就把路径加入到项目的头文件包含路径。用个脚本只不过是让项目的CMake文件看起来干净一些。
另外一个需要注意的是,OptiX版本7和之前的版本不兼容,就如同DX12和DX11不兼容那样。网上很多资料是关于OptiX 6的,请注意区分。
关于OptiX 7,我这里参考的就两份资料,一个是官方的概述文档:
一个是官方的SDK手册:
老实说语焉不详的地方很多很多,坑不少,不过至少不乱说。
还有一个主要参考的就是随SDK安装的样例程序。其中的optixSphere以及optixPathTracer是我主要参考的。
一个OptiX 7项目一般至少包括3个文件:
- 一个主程序文件,也被称为Host程序,是跑在CPU端的。负责构建OptiX运行环境。
- 一个着色器文件,也被称为Device程序,是跑在GPU端的。负责具体的渲染计算。
- 一个头文件,分别被主程序和着色器文件包含,负责定义Host和Device之间的传参接口。
而OptiX 7主程序这边的API设计,可以说和Vulkan/DX12什么的使用风格很像,就是不停的填表。有一定代码量,不过其实就是填写各种参数,格式相对固定,并没有太多变化。
commit: 57bf5c6b21f59d87f00caf76648a96598691f5d7 是我第一个OptiX 7的提交版本,包括了一个最为基础的OptiX 7应用程序。
CPU端主程序
我们从主程序开始看起。起手首先是包含OptiX的4个头文件,以及CUDA的一个头文件。然后写一些工具函数(检查API的返回值),简化后面的代码书写:
#include <optix.h>
#include <optix_function_table_definition.h>
#include <optix_stubs.h>
#include <optix_stack_size.h>
#include <cuda_runtime.h>
// help functions
#define checkCudaErrors(val) check_cuda((val), #val, __FILE__, __LINE__)
inline void check_cuda(cudaError_t result, char const *const func,
const char *const file, int const line) {
if (result) {
std::cerr << &#34;CUDA error = &#34; << static_cast<unsigned int>(result)
<< &#34; (&#34; << cudaGetErrorString(result) << &#34;) &#34;
<< &#34; at &#34; << file << &#34;:&#34; << line << &#34; &#39;&#34; << func << &#34;&#39; \n&#34;;
cudaDeviceReset();
exit(99);
}
}
#define checkOptiXErrors(val) check_optix((val), #val, __FILE__, __LINE__)
inline void check_optix( OptixResult res, const char* call, const char* file, unsigned int line )
{
if( res != OPTIX_SUCCESS )
{
std::cerr << &#34;Optix call &#39;&#34; << call << &#34;&#39; failed: &#34; << file << &#39;:&#39; << line << &#34;)\n&#34;;
exit(98);
}
}
#define checkOptiXErrorsLog(val) \
do { \
char LOG[2048]; \
size_t LOG_SIZE = sizeof(LOG); \
check_optix_log((val), LOG, sizeof(LOG), LOG_SIZE, #val, __FILE__, __LINE__); \
} while (false)
inline void check_optix_log( OptixResult res,
const char* log,
size_t sizeof_log,
size_t sizeof_log_returned,
const char* call,
const char* file,
unsigned int line )
{
if( res != OPTIX_SUCCESS )
{
std::cerr << &#34;Optix call &#39;&#34; << call << &#34;&#39; failed: &#34; << file << &#39;:&#39; << line << &#34;)\nLog:\n&#34;
<< log << ( sizeof_log_returned > sizeof_log ? &#34;<TRUNCATED>&#34; : &#34;&#34; ) << &#39;\n&#39;;
}
}
static void context_log_cb( unsigned int level, const char* tag, const char* message, void* /*cbdata */)
{
std::cerr << &#34;[&#34; << std::setw( 2 ) << level << &#34;][&#34; << std::setw( 12 ) << tag << &#34;]: &#34;
<< message << &#34;\n&#34;;
}接下来便是main函数,首先是设备上下文(显卡)的初始化。CUDA是lazy Init,所以直接调用一个没有实际作用的CUDA API进行初始化(cudaFree(0)),然后将CUcontext设置为0,告诉OptiX使用当前活动的(默认的)CUDA上下文。然后就是调用optixInit()进行OptiX的初始化,并且注册一个回调函数用于处理出错信息(非必需)。
// Initialize CUDA and create OptiX context
OptixDeviceContext context = nullptr;
{
checkCudaErrors(cudaFree(0));
CUcontext cuCtx = 0;
checkOptiXErrors(optixInit());
OptixDeviceContextOptions options = {};
options.logCallbackFunction = &context_log_cb;
options.logCallbackLevel = 4;
checkOptiXErrors(optixDeviceContextCreate(cuCtx, &options, &context));
}
接下来第二部分,就是在线编译Shader。也是非常常见的套路,就是填写一个结构体,将编译参数放进去。然后从磁盘读入shader文件(由Device程序,也就是设备程序编译产生,具体编译方法后述),然后调用optixModuleCreateFromPTX方法进行编译即可。
这里值得稍微说一下的就是,N卡的程序,本地的汇编语言叫SASS(好像和那个啥名字差不多),然后,有个PTX中间表示语言。因为PC显卡的型号众多,即便是同一家厂商的也常常相互不兼容,所以大部分时候我们只是将N卡GPU端的程序编译为PTX,然后在运行的时候再实时编译为具体型号的SASS,也就对应着实际执行的机器码。
// Create module
OptixModule module = nullptr;
OptixPipelineCompileOptions pipeline_compile_options = {};
{
OptixModuleCompileOptions module_compile_options = {};
#ifdef _DEBUG
module_compile_options.optLevel = OPTIX_COMPILE_OPTIMIZATION_LEVEL_0;
module_compile_options.debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_FULL;
#endif
pipeline_compile_options.usesMotionBlur = false;
pipeline_compile_options.traversableGraphFlags = OPTIX_TRAVERSABLE_GRAPH_FLAG_ALLOW_SINGLE_LEVEL_INSTANCING;
pipeline_compile_options.numPayloadValues = 2;
pipeline_compile_options.numAttributeValues = 2;
pipeline_compile_options.exceptionFlags = OPTIX_EXCEPTION_FLAG_STACK_OVERFLOW;
pipeline_compile_options.pipelineLaunchParamsVariableName = &#34;params&#34;;
My::AssetLoader assetLoader;
auto shader = assetLoader.SyncOpenAndReadBinary(&#34;Shaders/CUDA/draw_solid_color.optixir&#34;);
checkOptiXErrorsLog(optixModuleCreateFromPTX(
context,
&module_compile_options,
&pipeline_compile_options,
(const char*)shader.GetData(),
shader.GetDataSize(),
LOG, &LOG_SIZE,
&module
));
}之后就是创建着色器程序组。这里面就涉及到OptiX当中一个比较重要的概念,也是其它图形API(如Vulkan/DX12)等当中都有的概念(所以到底是谁先提出的呢?)。OptiX的总体架构,就是基于对于如下光线追踪算法流程的观察和总结:
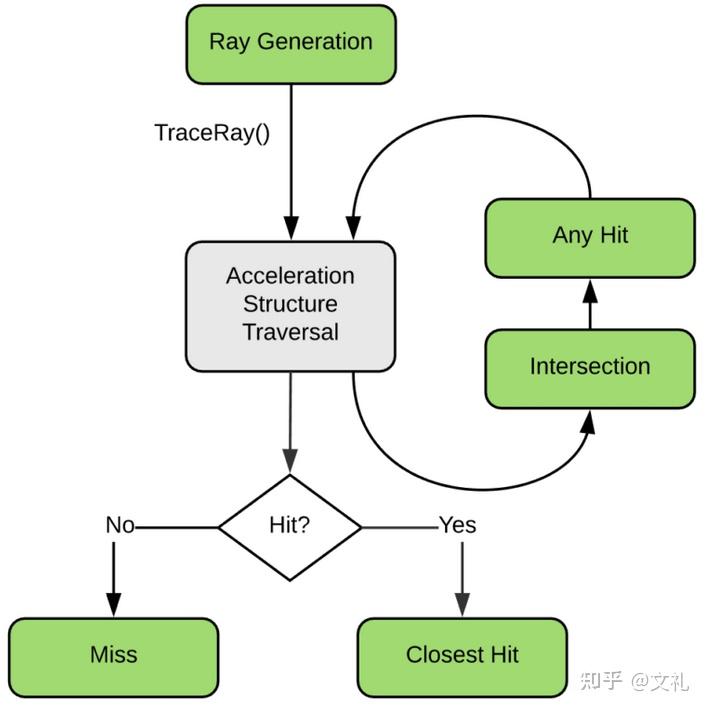
图片来源:https://developer.nvidia.com/blog/how-to-get-started-with-optix-7/
- 根据屏幕坐标产生光线
- 计算光线与场景的交
- 根据是否相交,进行不同的处理。如果没有相交,计算背景色。如果相交,计算材质对于光线的作用
Optix实际上就是将这个算法以非常高效的方式(主要在于数据结构的设计,以及根据GPU微架构特点进行的各种资源排布设计,很多地方貌似用了手写汇编)实现了,然后将上图绿色的部分扣洞洞扣出来,给我们做填空题(也就是可定制)。
每一个绿色的部分,在最为简单的情况下(比如我这次的实现),其实就对应一个程序,甚至是没有(无需定制)。但是对于比较复杂的情况,我们可能会需要根据不同的状态在相同的位置(洞洞)准备不同的程序。比如,在游戏当中,我们希望某个东西参与某个渲染计算,但是不参与另外一个渲染计算(比如我们不想让妹子的脸上有阴影。。。)。又比如纯粹因为性能考虑我们希望在某些计算当中用一个简化的计算版本,但是在另外一个计算流程当中用一个完整的,等等。
这就是所谓的着色器程序组概念的由来。你可以把它看成一个虚函数表,驱动它的是光线的类型(也就是打在每个光线上的tag)。通过给光线打不同的tag,可以调用组内不同的着色器,从而实现对于计算结果的控制。
当然我们这里只是要实现一个纯粹“物理正确”的路径追踪器,所以我们这里只有一种光线,每个组里也只有一个着色器。
这部分代码,同样的,和其它图形API都很像。对于一个最基本的OptiX程序,我们只需要一个着色器,就是RayGen(光线发射器)就可以了。
// Create program groups, including NULL miss and hitgroups
OptixProgramGroup raygen_prog_group = nullptr;
OptixProgramGroup miss_prog_group = nullptr;
{
OptixProgramGroupOptions program_group_options = {};
OptixProgramGroupDesc raygen_prog_group_desc = {};
raygen_prog_group_desc.kind = OPTIX_PROGRAM_GROUP_KIND_RAYGEN;
raygen_prog_group_desc.raygen.module = module;
raygen_prog_group_desc.raygen.entryFunctionName = &#34;__raygen__draw_solid_color&#34;;
checkOptiXErrorsLog(optixProgramGroupCreate(
context,
&raygen_prog_group_desc,
1, // num program groups
&program_group_options,
LOG, &LOG_SIZE,
&raygen_prog_group
));
// Leave miss group&#39;s module and entryfunc name null
OptixProgramGroupDesc miss_prog_group_desc = {};
miss_prog_group_desc.kind = OPTIX_PROGRAM_GROUP_KIND_MISS;
checkOptiXErrorsLog(optixProgramGroupCreate(
context,
&miss_prog_group_desc,
1,
&program_group_options,
LOG, &LOG_SIZE,
&miss_prog_group
));
}作为一个最基本的程序,我们用的是一个空场景。所以现在我们可以直接快进到将整个渲染管线链接起来的步骤了。在这个步骤里面最为频繁出现的就是stack(栈)的尺寸计算。这让我有一种恍然大悟的感觉。难怪我上一篇CUDA的时候被栈溢出搞得焦头烂额呢。
// Link pipeline
OptixPipeline pipeline = nullptr;
{
const uint32_t max_trace_depth = 0;
OptixProgramGroup program_groups[] = { raygen_prog_group };
OptixPipelineLinkOptions pipeline_link_options = {};
pipeline_link_options.maxTraceDepth = max_trace_depth;
pipeline_link_options.debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_FULL;
checkOptiXErrorsLog(optixPipelineCreate(
context,
&pipeline_compile_options,
&pipeline_link_options,
program_groups,
sizeof(program_groups) / sizeof(program_groups[0]),
LOG, &LOG_SIZE,
&pipeline
) );
OptixStackSizes stack_sizes = {};
for (auto& prog_group : program_groups) {
checkOptiXErrors(optixUtilAccumulateStackSizes(prog_group, &stack_sizes));
}
uint32_t direct_callable_stack_size_from_traversal;
uint32_t direct_callable_stack_size_from_state;
uint32_t continuation_stack_size;
checkOptiXErrors(optixUtilComputeStackSizes(&stack_sizes, max_trace_depth,
0,
0,
&direct_callable_stack_size_from_traversal,
&direct_callable_stack_size_from_state,
&continuation_stack_size));
checkOptiXErrors(optixPipelineSetStackSize(pipeline, direct_callable_stack_size_from_traversal,
direct_callable_stack_size_from_state,
continuation_stack_size,
2));
}最后一步就是设定shader的参数绑定表。用过blender等DCC工具,或者是诸如Unity/UE等材质编辑器的同学知道,如今在这些软件当中做材质就是连连看游戏,将各种预设模块组合在一起一通计算,最后输入到一个材质节点当中。
其实这个材质节点就是我们这里写的shader,而前面那些密如蛛网的节点图,无非就是在计算shader所需的参数。在OptiX里面,shader所需的参数是放在一个被称为SBT(Shader Binding Table,着色器绑定表)当中的。它看上去就如同一个Excel,一行是一个材质的数据,有多少行就有多少材质。当然,对于Ray Gen Shader,我们主要是用它传相机的参数。而对于目前我们这个最为简单的程序,我们只是传一个背景色给它:因为我们这个最为简单的Ray Gen Shader,其实就是为所有光线返回这个背景色。
// Set up shader binding table
OptixShaderBindingTable sbt = {};
{
CUdeviceptr raygen_record;
const size_t raygen_record_size = sizeof(RayGenSbtRecord);
checkCudaErrors(cudaMalloc(reinterpret_cast<void**>(&raygen_record), raygen_record_size));
RayGenSbtRecord rg_sbt;
checkOptiXErrors(optixSbtRecordPackHeader(raygen_prog_group, &rg_sbt));
rg_sbt.data = {0.462f, 0.725f, 0.f};
checkCudaErrors(cudaMemcpy(
reinterpret_cast<void*>(raygen_record),
&rg_sbt,
raygen_record_size,
cudaMemcpyHostToDevice
));
CUdeviceptr miss_record;
size_t miss_record_size = sizeof(MissSbtRecord);
checkCudaErrors(cudaMalloc(reinterpret_cast<void**>(&miss_record), miss_record_size));
RayGenSbtRecord ms_sbt;
checkOptiXErrors(optixSbtRecordPackHeader(miss_prog_group, &ms_sbt));
checkCudaErrors(cudaMemcpy(
reinterpret_cast<void**>(miss_record),
&ms_sbt,
miss_record_size,
cudaMemcpyHostToDevice
));
sbt.raygenRecord = raygen_record;
sbt.missRecordBase = miss_record;
sbt.missRecordStrideInBytes = sizeof(MissSbtRecord);
sbt.missRecordCount = 1;
}好了,到了这里我们所有(CPU端的)前期的准备工作完成,管线搭建完毕,要开始按下渲染按钮了:
CUstream stream;
checkCudaErrors(cudaStreamCreate(&stream));
Params params;
params.image = reinterpret_cast<uchar4*>(img.data);
params.image_width = image_width;
CUdeviceptr d_param;
checkCudaErrors(cudaMalloc(reinterpret_cast<void**>(&d_param), sizeof(Params)));
checkCudaErrors(cudaMemcpy(
reinterpret_cast<void**>(d_param),
&params, sizeof(params),
cudaMemcpyHostToDevice
));
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
checkOptiXErrors(optixLaunch(pipeline, stream, d_param, sizeof(Params), &sbt, image_width, image_height, 1));
cudaEventRecord(stop);
checkCudaErrors(cudaDeviceSynchronize());
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
printf(&#34;Rendering time: %f ms\n&#34;, milliseconds);
img.SaveTGA(&#34;raytracing_optix.tga&#34;);
img.data = nullptr; // to avoid double free最后是打扫战场:
// clean up
{
checkCudaErrors(cudaFree(reinterpret_cast<void*>(d_param)));
checkCudaErrors(cudaFree(reinterpret_cast<void**>(sbt.raygenRecord)));
checkCudaErrors(cudaFree(reinterpret_cast<void**>(sbt.missRecordBase)));
checkOptiXErrors(optixPipelineDestroy(pipeline));
checkOptiXErrors(optixProgramGroupDestroy(miss_prog_group));
checkOptiXErrors(optixProgramGroupDestroy(raygen_prog_group));
checkOptiXErrors(optixModuleDestroy(module));
checkOptiXErrors(optixDeviceContextDestroy(context));
}和上一篇类似,写CUDA/OptiX程序需要时刻注意的就是,CPU可见的内存和GPU可见的内存,很多时候不是一回子事情。我们显卡上几G十几G的显存,叫device memory,往往是对CPU不可见的。所以,在CUDA/OptiX程序当中,我们要声明什么结构体或者类的实例,都是需要先在CPU端构造一个,然后在GPU端申请一块一样大的显存,然后让GPU拷贝过去。
这里面特别需要注意的就是带有虚函数的类的实例。因为虚函数会产生虚函数表,而虚函数表里面存的都是指针。这个指针拷贝过去是没有用的。
所以对于这种情况,往往我们会需要重新为GPU写一个简化版本的结构体/类,不带虚函数表的。或者,直接在GPU端实例化,然后只是拷贝虚函数表之外的,成员字段部分(如果字段当中含有指针,则一样需要递归深度拷贝)
设备端Shader
设备端Shader非常简单,除了一些工具函数(如clamp,Linear2SRGB)之外,主程序就是返回一个固定的背景色。这个背景色是我们通过SBT传递过来的。
extern &#34;C&#34;
__global__ void __raygen__draw_solid_color() {
uint3 launch_index = optixGetLaunchIndex();
RayGenData* rtData = (RayGenData*)optixGetSbtDataPointer();
params.image[launch_index.y * params.image_width + launch_index.x] =
make_color( make_float3( rtData->r, rtData->g, rtData->b ) );
}另外,我们还定义了一个Params,相当于图形API当中的ConstantBuffer,用于传递一些全局性的(不是给特定着色器组的)参数:
extern &#34;C&#34; {
__constant__ Params params;
}CPU/GPU共享头文件
就是用来定义CPU和GPU之间传递的参数结构,尽量使用一些基本型。
#include &#34;geommath.hpp&#34;
struct Params
{
uchar4* image;
unsigned int image_width;
};
struct RayGenData
{
float r,g,b;
};运行结果:
 |
|



 发表于 2023-1-8 10:42:30
发表于 2023-1-8 10:42:30